

A few messy development notes for everyone to laugh at.
Choosing the stack
Before building the new platform, I sat down and thought through what we actually needed:
Deploy once, host multiple competitions, and keep a permanent practice platform online so operations do not have to keep suffering.
The club runs at least four competitions every year: MoeCTF, Mini LCTF, D3CTF/LCTF, and the high-school event. After every competition, operations had to painfully move all challenges over to an archive platform. For MoeCTF and Mini LCTF, we sometimes even needed to host events directly on that archive platform. The CTFd setup we had been using kept running into the same issues:
- it could only host a single competition at a time;
- deployment and upgrades were a bit annoying;
- performance was a real problem;
- migrating and merging competition data was a complete disaster.
So if we wanted future events to stop being this painful, it was probably time to switch platforms.
A bit of background
Ever since I started operating MoeCTF 2020, I had been trying to find a platform that could fix CTFd’s pain points. The options I looked at included:
- Zhao’s buuoj.cn: their multi-event solution does not seem to be open source, and I was not eager to keep monkey-patching CTFd forever;
- HackTheBox: not open source, but the overall product model was worth studying;
- Mellivora: written in PHP, and after looking through it, the feature set still did not feel like a match.
Then I procrastinated from 2020 all the way into the first half of 2022. A bunch of unrelated trouble kept getting in the way, and I never had a large enough chunk of uninterrupted time to write a serious project.
Then summer 2022 showed up, around May or so.
One month before miniL: this year miniL must use the new platform.
Two days before miniL: I am not finishing this in time. Send in CTFd.
Right after miniL: MoeCTF this year absolutely has to use the new platform.
And that was the start of this whole miserable journey.
Language? Framework?
I went through the usual candidates:
- Java: the language and ecosystem are mature, but after reading a few supposedly high-quality open-source projects and seeing names like
xxxWrapperHandlerControllerImpl, I started losing the will to live; - Python: when I started this, Python 3.9 still had the GIL. A proud single-core warrior;
- C#: I had written a bit of WinForms before and thought the language design looked pretty impressive, so I went to read the ASP.NET docs. After one pass through the docs I still had no idea how a request actually reached an endpoint. It somehow just worked. Then the machine-translated Microsoft docs and weird compatibility changes scared me off;
- C++: I genuinely considered writing a server with Qt’s SocketServer, but… why? And I would have had to build my own ORM story too;
- NodeJS: the language itself was already a hard sell for me;
- Go: after a few hours of beginner tutorials following dinner - or maybe breakfast - I decided it was beautiful in its simplicity and instantly declared myself a Go expert.
So in the end I jumped into the Go pit. The web framework was gin, and the database stack was PostgreSQL plus GORM.
On the frontend side, I went back and forth between Vue and React for a while, and eventually settled on Vue 3. Frontend frameworks all feel broadly similar once you start using them, but Vue 3’s way of organizing code fit my intuition better.
The component library I used was Naive UI.
SSR or CSR?
I personally lean toward server-side rendering. Users get content immediately when they open the page, and frontend development can be a bit easier too because you need fewer placeholders, skeletons, and asynchronous loading hacks. But after looking around the Vue ecosystem, the situation was not nearly as good as I had hoped. Most SSR solutions were really aimed at NodeJS backends, and I could not find anything both stable and pleasant to pair with a Go backend. Most go + vue projects I found were fully split frontend/backend setups.
So I eventually chose client-side rendering. Since both the frontend and the backend live on the same server anyway, I was not too worried that it would hurt user experience all that much.
In the end, the plan became a decoupled Go backend plus Vue 3 frontend.
Database design
Once the stack was fixed and the initial scaffold was in place, the next step was database design.
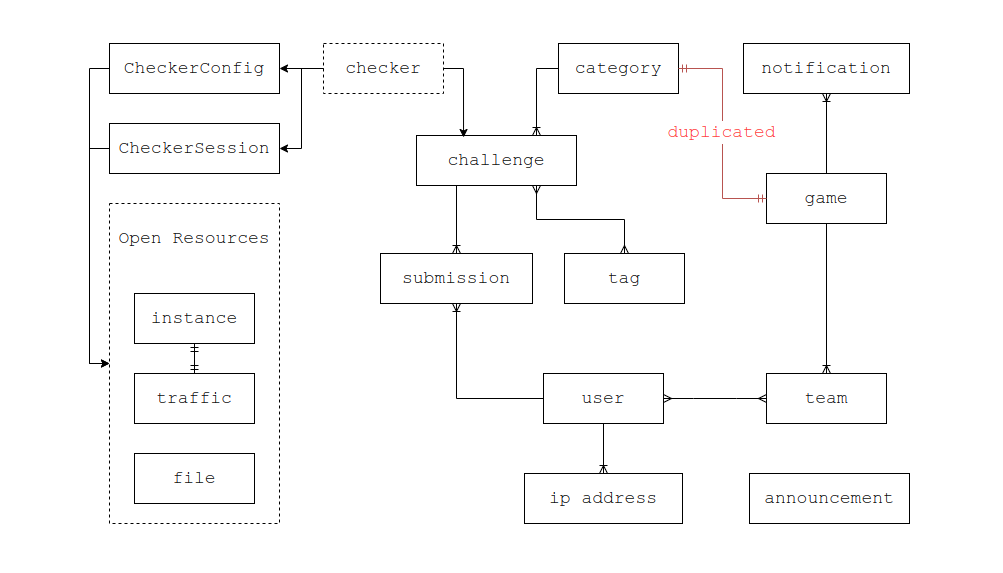
The biggest difference between Cyber Terminal and CTFd is that Cyber Terminal can host multiple competitions - even simultaneously - while also handling challenge archival automatically. So the schema had to borrow some ideas from CTFd but also account for those extra requirements.
The database design looked like this:
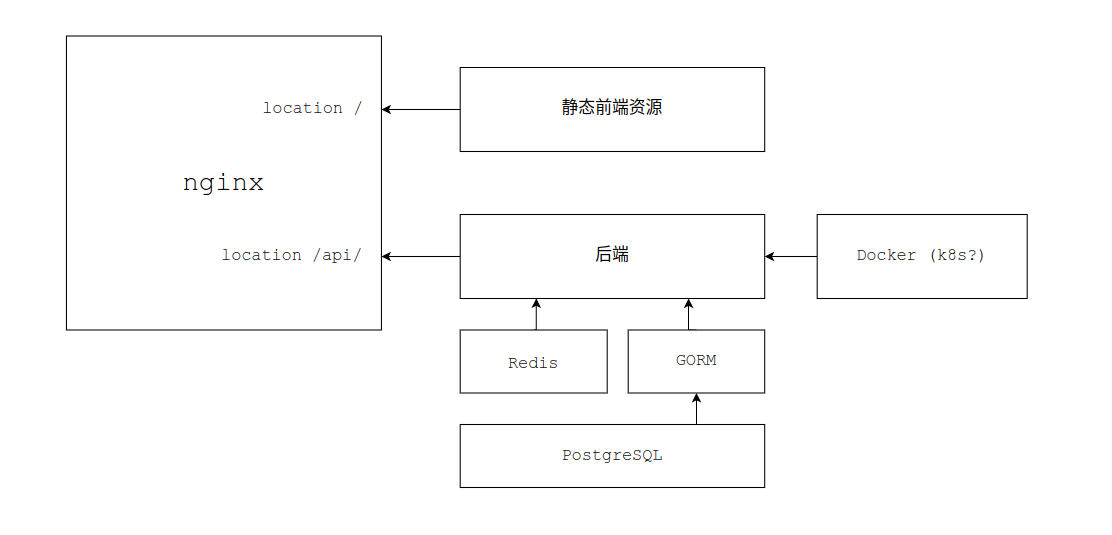
And the overall site architecture looked like this:
Separating game and category turned out to be a design mistake. I plan to merge them in the next major update.
At the time, my thinking was that if the platform was going to support a practice arena, then it ought to have some concept of a “category,” and archived competitions could naturally live under the same model. But for challenges themselves, forcing each one into exactly one category felt too rigid. So I changed concepts like web and pwn from category into tag, which let a challenge carry multiple tags and still get categorized that way. The original category concept then became a way to organize where challenges came from.
Later on, though, I realized that category and game were effectively a one-to-one relationship in the implementation. Splitting them apart only made database operations more annoying. It was completely unnecessary, and I ended up writing a lot of ugly code around it for no good reason.
CTF challenge types vary a lot. There are static-attachment challenges, dynamic-container challenges, dynamically distributed attachments for anti-cheating, and even ACM-style judged problems. The requirements are very different from one type to another. So I introduced the concept of a checker to represent a challenge type. A challenge can attach polymorphically to a specific checker, and all checker-specific data lives inside the corresponding checker implementation.
In practice, a checker also needs both challenge-scoped storage and user-scoped storage, so I introduced checkerConfig and checkerSession. The former is a one-to-one association with a challenge and stores configuration for that challenge type: static flags, dynamic flag templates, static attachments, container images and settings, and so on. The latter is uniquely associated with challenge + user; it gets created automatically when a user tries to access a challenge, and it can store things like one-off generated dynamic flags, the state of a started container, access information, and so on.
The way checker is organized is a little different from CTFd. CTFd exposes things like challenges and flag types to plugins through internal APIs, and I did not feel that extra split was really necessary, so I rolled them into a single checker concept. CTFd also has no built-in session model, which means plugins have to manage their own tables anyway. At that point it felt cleaner to make the session concept part of the design too.
Dev Log 01
I must have been out of my mind to choose GORM
Time jumps back to June. After finally finishing a pile of miscellaneous nonsense, I was ready to start. I spent half a day locking down the stack and framework choices, designed the database layout, and then jumped into the backend.
Because I wanted something convenient, I picked GORM, which looked polished and powerful.
The result? Four lines of code, two pitfalls.
Why four lines? Because three of them were
if err != nil { return nil, err }.
First, GORM’s API is not actually consistent:
// The return value is *Cmd, so you can keep chaining calls,
// though after First I honestly have no idea what else you would chain.
// If you want the error from this line, you need *Cmd.Error,
// which yields an errors.Error.
err := db.Model(&models.User{}).Where("name = ? and verified = ?", name, true).First(&user).Error
// But in the Association API, the return value is already errors.Error.
// If you then try to call Error() again, you just end up with an err string.
err := db.Model(&models.Team{}).Where("id = ?", teamID).Association("Users").Find(&users)Second, the example in GORM’s own docs does not run:
// The docs include this example for a custom JSON field.
type JSON json.RawMessage
// Scan scan value into Jsonb, implements sql.Scanner interface
func (j *JSON) Scan(value interface{}) error {
// Problem: in practice value came back as a string here,
// so the cast failed immediately.
bytes, ok := value.([]byte)
if !ok {
return errors.New(fmt.Sprint("Failed to unmarshal JSONB value:", value))
}
result := json.RawMessage{}
err := json.Unmarshal(bytes, &result)
*j = JSON(result)
return err
}
func (j JSON) Value() (driver.Value, error) {
if len(j) == 0 {
return nil, nil
}
// Oddly enough, this writes out a []byte.
// My guess is that the read/write behavior is not even consistent.
return json.RawMessage(j).MarshalJSON()
}And then there is Association Mode, which really feels half-finished.
As far as my very average database-theory memory goes, relational models come in three shapes: one-to-one, one-to-many, and many-to-many. Then I opened the docs and found four: belongs to, has one, has many, and many to many. That was enough to make me search what is the difference between has one and belongs to?, and apart from the first result being ThinkPHP5, almost every other result was GORM.
Me: wow, did I learn database theory for nothing?
(searches)
Me: …
Me: what do you mean you invented your own relationship model?
At first I assumed it would all be close enough, so I tried to write it by intuition. In my earlier design, submission had one-to-many relationships with both user and challenge, and in practice I needed to look up user from submission and submission from user.
Me: then
submissionbelongs tochallenge, andchallengehas manysubmissions.Me: that sounds perfectly fine.
(writes it, runs it, explodes)
Me: ?
After reading the docs more carefully, I realized that belongs to and has one are both one-to-one relationships. So yes, that one was on me.
Then I tried to understand what the difference between those two one-to-one models even was:
// The docs call this belongs to.
type Game struct {
ID uint
...
Category *Category // <-
CategoryID uint
}
type Category struct {
ID uint
...
}
// And this one is called has one.
type Game struct {
ID uint
...
CategoryID uint
}
type Category struct {
ID uint
...
Game *Game // <-
}Both versions generate a games table with a category_id column and the exact same relationship constraint. The only difference is whether Game contains Category or Category contains Game.
Me: so what is the actual difference here? What kind of feature is this?
Me: fine, then if I only keep one key and put a pointer to the other struct on both sides, that should be okay, right? Loading still requires explicit preload anyway, so it should not recurse forever.
(writes it, runs it, explodes)
Me: unbelievable.
That led to an awkward situation: no matter which direction I modeled it, only one side could really use Association Mode. The other side still needed manual query conditions:
// Use Association to find category from game? Fine.
db.Model(&models.Game{}).Where("id = ?", gameID).Association(&models.Category{}).First(&category)
// Use Association to find game from category? Not happening.
db.Model(&models.Category{}).Joins("inner join games on games.category_id = categories.id and categories.id = ?", categoryID).First(&game)
// At which point why not just write this instead?
db.Model(&models.Game{}).Where("category_id = ?", categoryID).First(&category)
// What is the point of Association Mode, exactly?has many had the same sort of problem.
For most of the rest of development I basically kept GORM in Debug mode the entire time. Every time I wrote a query, I ran it once just to inspect the SQL it generated and see whether it even matched what I thought I had asked for. That uncovered all kinds of other strange issues, too many to list here.
Me: what kind of SQL is this even generating? In one part of the docs, a
Usergets created with aLanguagesfield, and then in the filtering example it suddenly turns intocodes. Did nobody think to show the original struct definition even once?