

Intro
Back in college I opened several giant rabbit holes, projects like Ret2Shell and Forensics Cat. One reason I chose grad school instead of going straight to work was that I wanted a little more time to actually build those ideas out. Over the years, the results have not been bad at all. Ret2Shell is now fairly complete, but Forensics Cat is still mostly a handful of documents, and the file-system parsing part - one of its most important pieces - is still largely the work of cdcq.
While pushing my thesis forward, I found myself itching to make the disassembler side of it a bit bigger, at least a bit more interactive so it could stand next to IDA. So I spent quite a bit of time on the design, built out a general data-access layer, cleaned up and unified things like Instruction, and then hacked together a reusable UI. The whole application ended up being named Regressor.
Once that was mostly in place, I suddenly remembered Forensics Cat. Since the data-access layer already existed, all I really needed was a compatibility layer that could treat disk images, file systems, and related sources like folders, expose a general and simple walkdir-style API, and borrow a few scanning ideas from mature forensic tools like plaso. At that point, Forensics Cat would almost build itself. So I did exactly that. From the first year of grad school to the third, I kept grinding on it and eventually ended up with this:
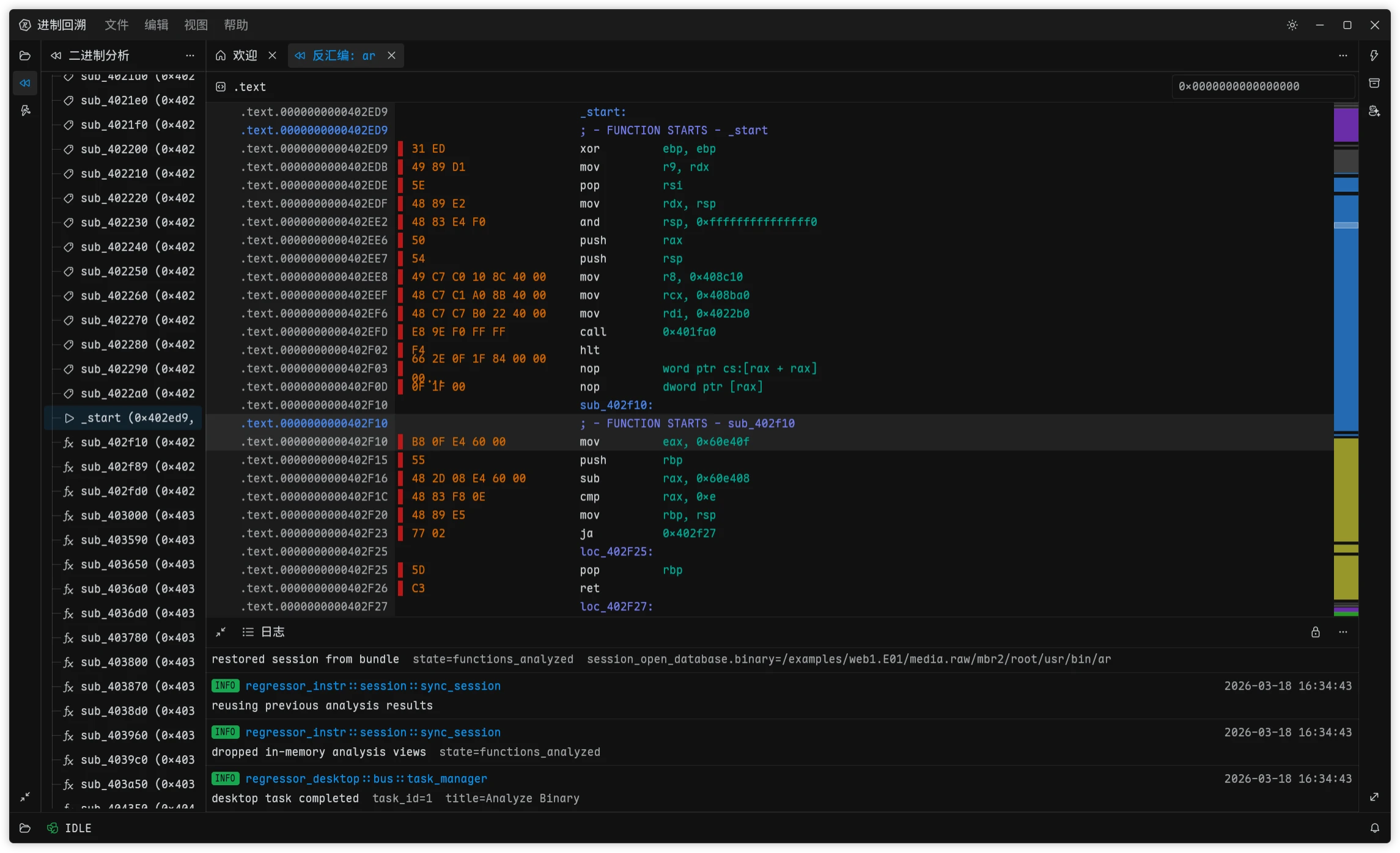
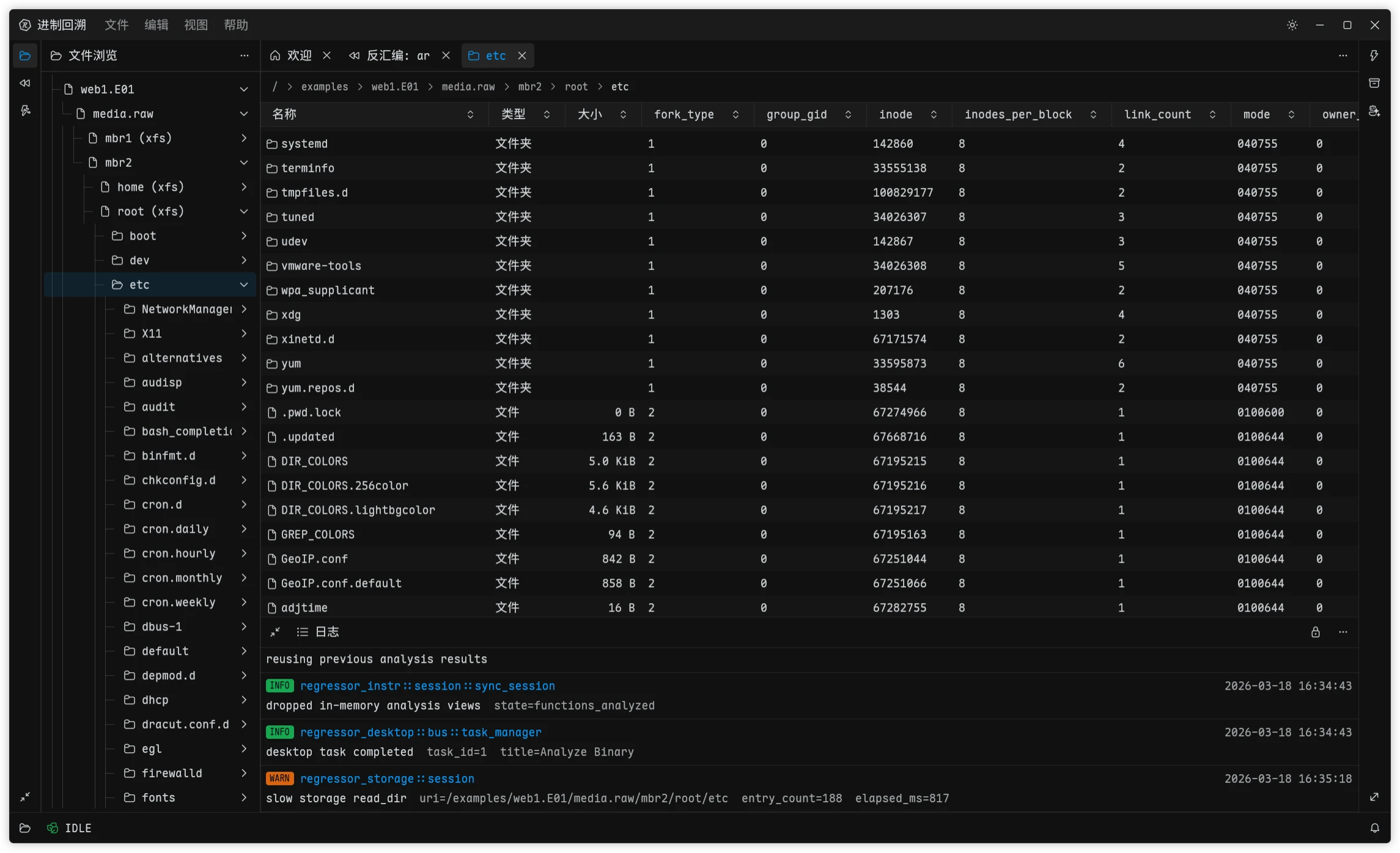
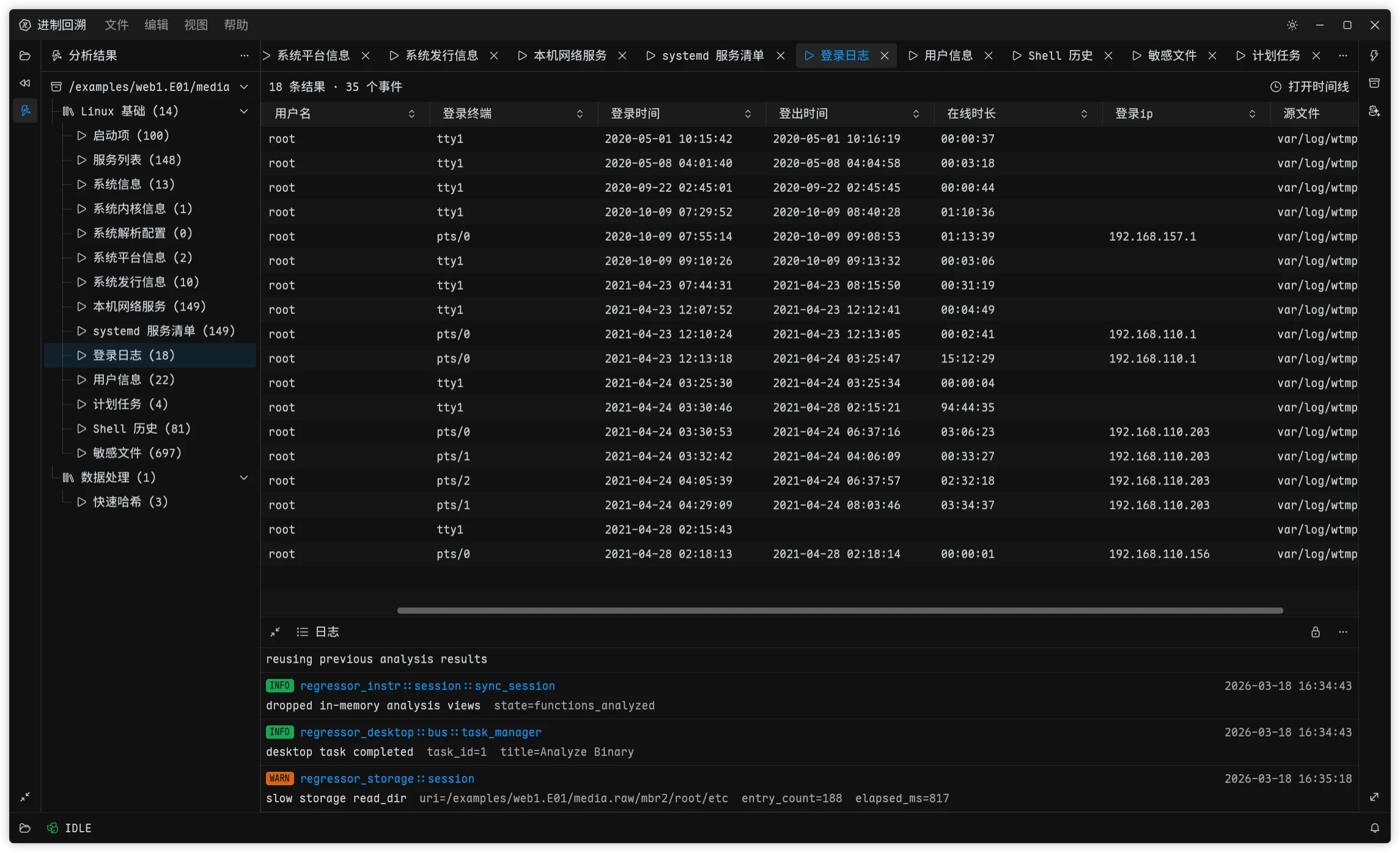
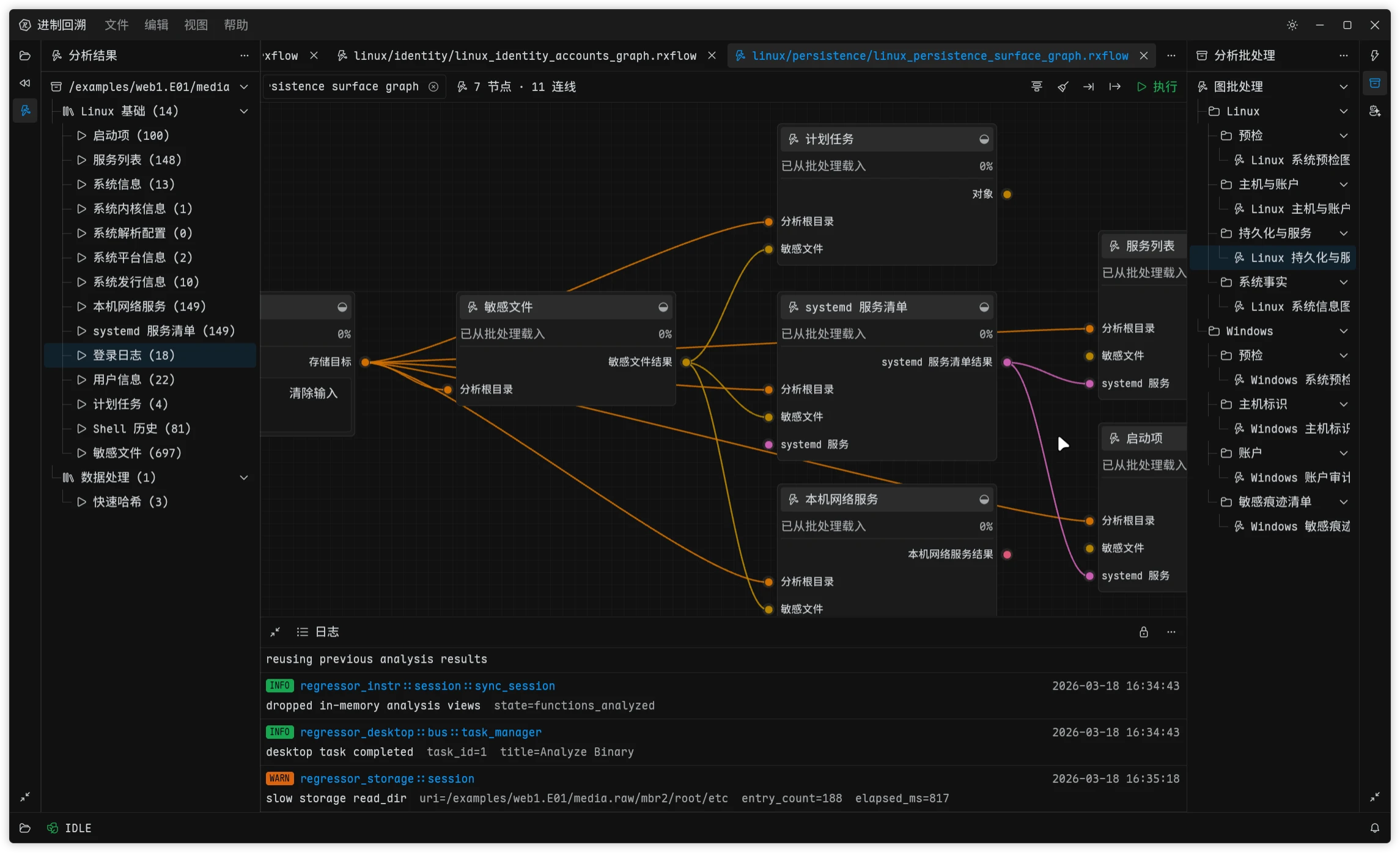
When I first added forensic capabilities to Regressor, I was not planning to maintain a full low-level parsing stack myself. There is simply too much work in disk images, partition tables, and file systems. Back when I first imagined Forensics Cat during undergrad, I had already looked into libyal. Formats like EWF, QCOW, VHDX, and NTFS all come with piles of RFCs and implementation details, and something like NTFS - after decades of Microsoft patches piled on top of each other - is especially painful. Building all of that from scratch means a massive up-front investment, slow format coverage, and plenty of time wasted on things that are officially called features but are functionally bugs.
But right when I was about to wrap libyal in a Rust library, I ran into something the maintainer was working on at the time: keramics. It already had fairly complete read-only support in Rust for EWF, QCOW, VHD/VMDK, GPT, MBR, APM, NTFS, FAT, ext, and HFS. That meant Regressor only needed a regressor-storage bridge layer on top of it, plus a cleaner virtual abstraction for the whole system. Image browsing, partition probing, and file-system mounting started working quickly.
As Regressor kept growing, the cracks became harder and harder to ignore. Two facts turned into real blockers. First, its access model does not fit my current forensic use cases. You may have noticed a “slow read” line in the log shown in the screenshots above. That comes straight from the way keramics is designed: it uses a state-machine model throughout the library, which means none of the formats it supports can really do concurrent I/O. Regressor already has a fairly solid concurrency model of its own, but once a request reaches the keramics-backed driver it collapses back to a single thread. As analysis tasks pile up, the app starts feeling painfully sluggish even though CPU and memory usage both look low.
Second, its library-level panic risk is already too high for forensic workloads.
The concurrency problem
Regressor’s storage layer abstracts raw byte sources as DataSource, and the core API is offset-based reads:
fn read_at(&self, offset: u64, buf: &mut [u8]) -> Result<usize, _>;The upside of this interface is obvious: callers do not need to care about a shared cursor, they do not need to guess where another thread just read to, and they can read any range of bytes from any position as long as they have the data source. Concurrency stops being a problem at the API level. Regressor’s hash scheduling, probe cache, and telemetry are all built on top of this model.
keramics, on the other hand, centers everything around DataStream. Reads depend on an internal cursor, so the shape is still basically Seek + Read:
fn read(&mut self, buf: &mut [u8]) -> Result<usize, _>;
fn seek(&mut self, pos: SeekFrom) -> Result<u64, _>;There is nothing inherently wrong with this interface. Plenty of classic forensic libraries are designed like that. The problem appears the moment a host wants to adapt it to read_at semantics. At that point the bridge layer can only translate each random read into “take the lock, move the cursor, read the bytes.” Since the handle must keep state for the cursor position, true concurrency is impossible. In Regressor’s current bridge implementation, that path can only be marked as Serialized + Expensive, which effectively wipes out all the performance work Regressor has already done for parallel reads. The analysis side already has a fast chunked hashing strategy built around concurrent reading, but as long as the keramics integration remains shaped like this, it has to fall back to sequential reads.
This conflict also gets more expensive as the stack gets deeper. When you have an image containing partitions, a partition containing a file system, and the file system containing an archive or virtual disk, every layer wants to see a stable read-only offset-based source. If the very bottom still depends on a shared cursor, every cleaner abstraction above it eventually gets dragged back to the same question: is the backend fundamentally serial?
Panic risk inside the library
The second serious issue is how it fails when used as a library. Regressor deals with external evidence, so inputs are untrusted by definition. In this context, the worst outcome is not “we cannot read this sample”; it is “the library explodes and takes the whole application down with it.” The first case can usually be turned into a structured error saying the sample is unsupported, corrupted, or missing a sidecar. The second case is much nastier. You cannot reliably catch it from the host side, and if you try to build unwind-based recovery you end up writing a pile of ugly code just to imitate C++-style try/catch behavior.
Even in the current implementation of keramics, you can still find unwrap calls built on assumptions like “this state should always exist.” For example, along the vhdx path that reads the block allocation table, there is a direct self.block_allocation_table.as_ref().unwrap(). For a standalone tool, assumptions like that can sometimes be tolerated. In a long-running desktop application or analysis runtime, they mean malformed samples or missed implementation branches may cause a hard crash instead of a proper error.
There is also an engineering issue on the Regressor side: to integrate keramics, the bridge layer wraps DataStream in a shared lock. Once a panic happens somewhere underneath, that lock can be poisoned, and later accesses start failing with secondary errors such as LockPoisoned. In other words, the damage does not necessarily stop at the first failure site; it can keep propagating through shared state. For a forensic library, that price is far too high. Parsers should fail conservatively in the presence of bad input, not turn an invalid internal assumption into a source of instability.
Architecture
Given those issues, sticking with keramics would only make the rest of the development work harder over time. Better to leave early and write my own thing. AI tooling is strong enough these days that once the infrastructure is in place, it should be able to help fill in parser implementations for various file systems without introducing anything too terrible.
So I decided to build a cleaner, more usable API to replace keramics.
The project is called Wired Xploring Target Layer Accessor. Yes, that really is what the acronym stands for. No hidden meaning.
The project is open-sourced at Reverier-Xu/wxtla and published on crates.io.
Layer 1: data sources and capability descriptions
At the bottom of the stack is the data-source model in core. DataSource keeps only the two most fundamental operations: read by offset and query total size. On top of that, DataSourceCapabilities explicitly describes the backend’s concurrency properties, seek cost, and preferred block size. That matters because the upper layers can choose between sequential reads and parallel chunking directly from capability declarations instead of trying to infer performance from implementation details. The same idea applies inside the parsers: metadata reads, content reads, sparse mappings, and parent-image fallback can all be built on the same interface without adding one more shared-cursor adapter for every format.
The other wrappers in core follow the same rule. SliceDataSource re-exposes a logical byte range as a new source, so partitions, image extents, and file contents can all reuse it. ProbeCachedDataSource only caches small-window reads from the first 64 KiB during probing, which keeps dozens of format detectors from re-reading the same header bytes again and again. ObservedDataSource records read count, average read size, seek distance, and read latency so later performance analysis and scheduling policies can rely on real measurements instead of guesswork.
Layer 2: probing and related-source resolution
wxtla turns format detection into a standalone mechanism. FormatDescriptor and FormatKind describe what a format is, FormatProbe contains the per-format detection logic, ProbeContext provides cached reads, and ProbeRegistry collects and orders probe results. The rule for probing is also clear: do only the small amount of reading needed to confirm a format, and do not pre-parse the whole image at this stage. That distinction matters a lot for a host like Regressor, which performs automatic mounting and recursive probing frequently. If probing gets too heavy, the whole storage layer becomes sluggish.
The other critical boundary is related sources. EWF segments, QCOW backing files, VHD/VHDX parent images, and sparsebundle bands are not really problems “inside the current file”; they are cases where the current object refers to another source. wxtla does not let parsers touch the host file system directly. Instead, it passes SourceHints with explicit SourceIdentity and RelatedSourceResolver. RelatedPathBuf is also only a lexical relative path, not a platform-aware path type. That way, parsers only declare what they need, while file discovery, workspace cache hits, and access policy remain the responsibility of the host. That boundary is what determines whether the same parser can be reused across different runtime environments.
Layer 3: read-only object interfaces split by domain
Above core, wxtla does not build a single unified VFS layer. Instead, it splits interfaces into four domains: images, volumes, filesystems, and archives. After an image driver opens a source, it still implements DataSource, but it can also expose format-specific semantics such as logical sector size, physical sector size, sparsity, and whether a backing chain exists. A volume-system driver returns a set of VolumeRecord values containing only stable information such as index, byte span, name, and role, and then uses open_volume to reopen the corresponding logical volume as a new DataSource. That keeps partition tables focused on describing what volumes exist and what byte ranges they cover, rather than deciding UI structure or mount behavior ahead of time.
The file-system and archive layers follow the same philosophy. FileSystem exposes a root node, node metadata, read_dir, and open_file; Archive exposes entry metadata, read_dir, and open_file. Whether it is a FileSystemNodeId or an ArchiveEntryId, the identifier is opaque; internal keys are not just path strings pretending to be identities. That leaves path normalization, mount-point stitching, display names, and access control to the product layer, while the parser core keeps only stable structural identifiers and content access.
Layer 4: how format modules are organized
At the implementation level, wxtla also tries hard to avoid centralization. Each format module declares its own descriptor, carries its own probe, and submits registration data through inventory::submit!. The formats/ directory only assembles those scattered entries into a probe registry instead of maintaining one ever-growing central dispatch table. That way, when you modify a format, its definition, probe, and open logic usually stay within the same module boundary, which makes maintenance much cheaper.
Nontrivial formats also settle into a fairly stable internal split. mod.rs handles exports and registration; low-level structs parse fixed-layout objects such as headers, entries, and tables; parser.rs coordinates metadata reads and consistency checks; and image.rs, system.rs, filesystem.rs, or archive.rs turn the parsed result into a readable object surface. Caches are also kept inside the format whenever possible, such as chunk caches, block translation tables, extent caches, and allocation-unit decompression caches. The benefit is that local optimizations do not leak into the whole core, and different formats do not have to fight over one giant shared caching framework.
Layer 5: error modeling and panic constraints
The final architectural constraint in wxtla is that failure paths are treated as part of the design. The core layer keeps only a small set of stable errors: I/O errors, UnexpectedEof, InvalidRange, InvalidFormat, InvalidSourceReference, and NotFound. Individual formats can attach their own context, but the outer behavior must stay consistent: if the sample is corrupted, an offset is invalid, a related source is missing, or a feature is unsupported, the parser returns a structured error rather than exposing the problem through a panic. Combined with rules such as checked_*, try_from, and validate-before-decode, the goal of wxtla is not just “cleaner code”; it is making parsing behavior predictable in the face of real-world evidence.
With those layers in place, wxtla ends up with a very clear role: it only interprets bytes into stable read-only objects such as images, volumes, file systems, and archives. Then regressor-storage adapts those objects into StorageSession and MountedFilesystem. That way, the same access chain can be reused while keeping the parser and the host from tangling their responsibilities together again.
Refactoring Regressor
For Regressor, this rewrite moved most of the format-parsing work into wxtla. That lets the storage module itself stay much simpler, and it removes the need for dedicated compatibility layers or bridges just to deal with concurrent access. The desktop app, analysis runtime, and Python bridge depend on StorageSession, MountedFilesystem, and DataSource, not on any one format implementation. As long as that host-facing interface stays stable, Regressor’s existing architecture does not need invasive surgery.