

前言
大学的时候我曾经挖了好几个巨型坑,比如 回归终端,取证猫 什么的,之前选择读研而不是直接工作其实也是想多留点时间给这些东西都做一做。 这几年熬下来,其实成果还算不错,回归终端 已经具备比较完善的功能了,但是 取证猫 仍旧还是寥寥几篇文档,里面比较重要的文件系统格式解析部分还是 cdcq 写的。
在推进毕设的时候,因为我的毕设是聚焦反汇编器这一块的,有点心痒痒想给他写的稍微大一点,至少让它 Interactive 一点,这样可以对标 IDA,于是我在设计上下了不少功夫,扩展出来一套通用的数据访问层,给 Instruction 什么的都整合了一遍, 然后搓了个能复用的 UI,软件整体命名为 进制回溯(Regressor)。
搓差不多的时候我忽然想起来取证猫的事,既然数据访问层已经有了,接上去一个能把镜像、文件系统等设施当文件夹使的兼容层,然后导出一套通用并且足够简单的 walkdir 方法,再白嫖一点 plaso 之类成熟取证软件的扫描思路, 取证猫不就做完了么,于是说干就干,后面就开始推进开发,从研一闷头搓到研三,搞出来这么个玩意儿:
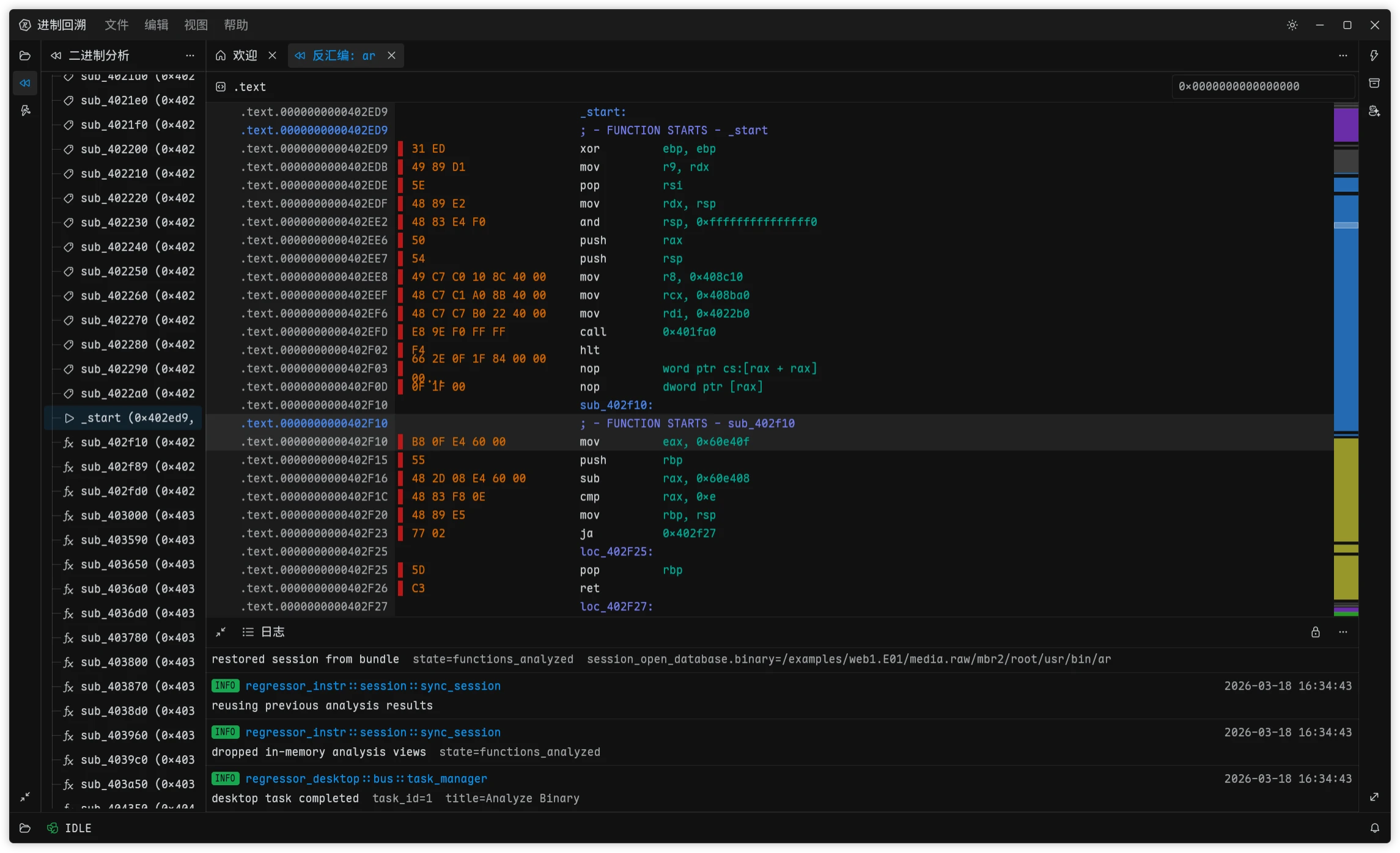
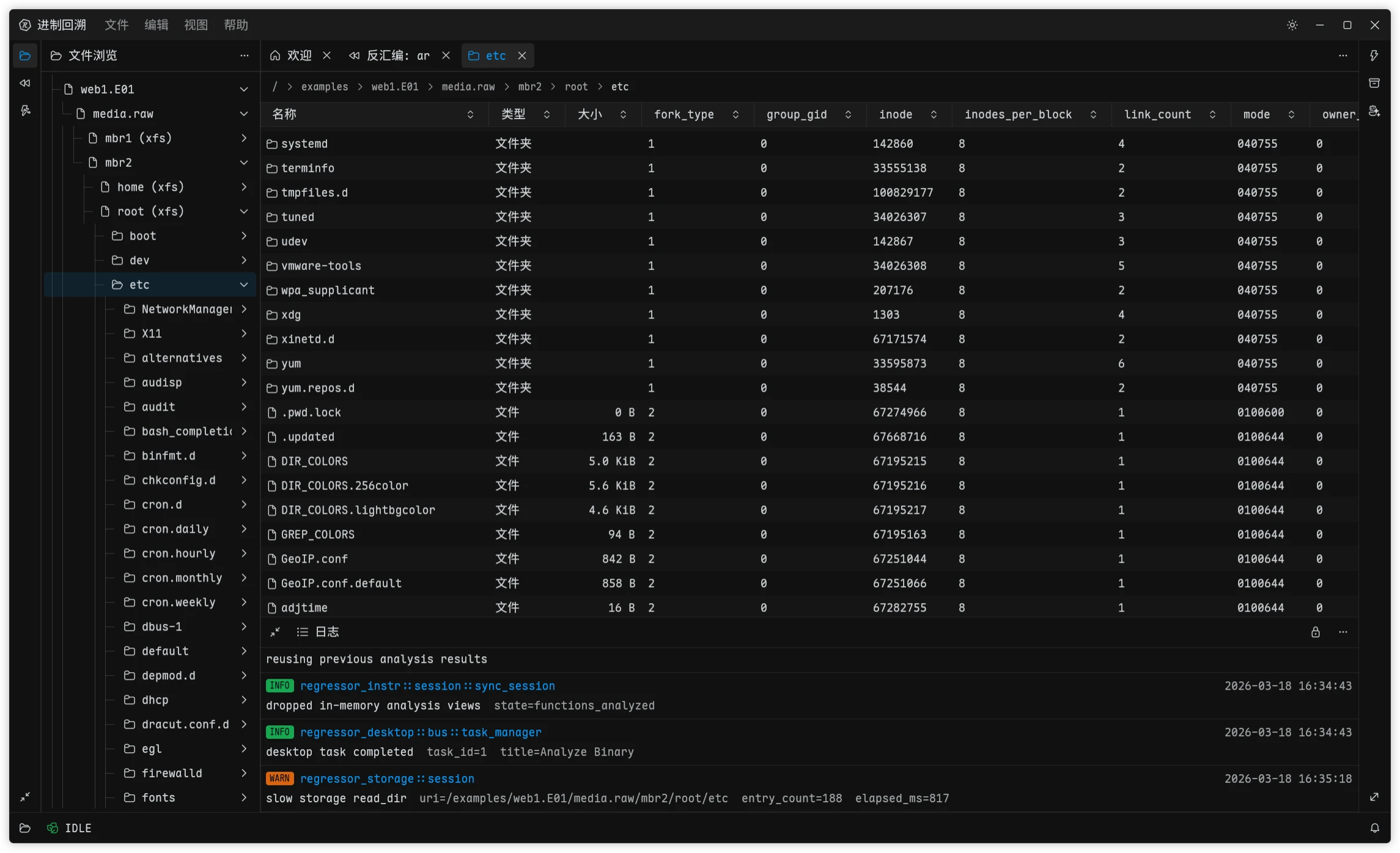
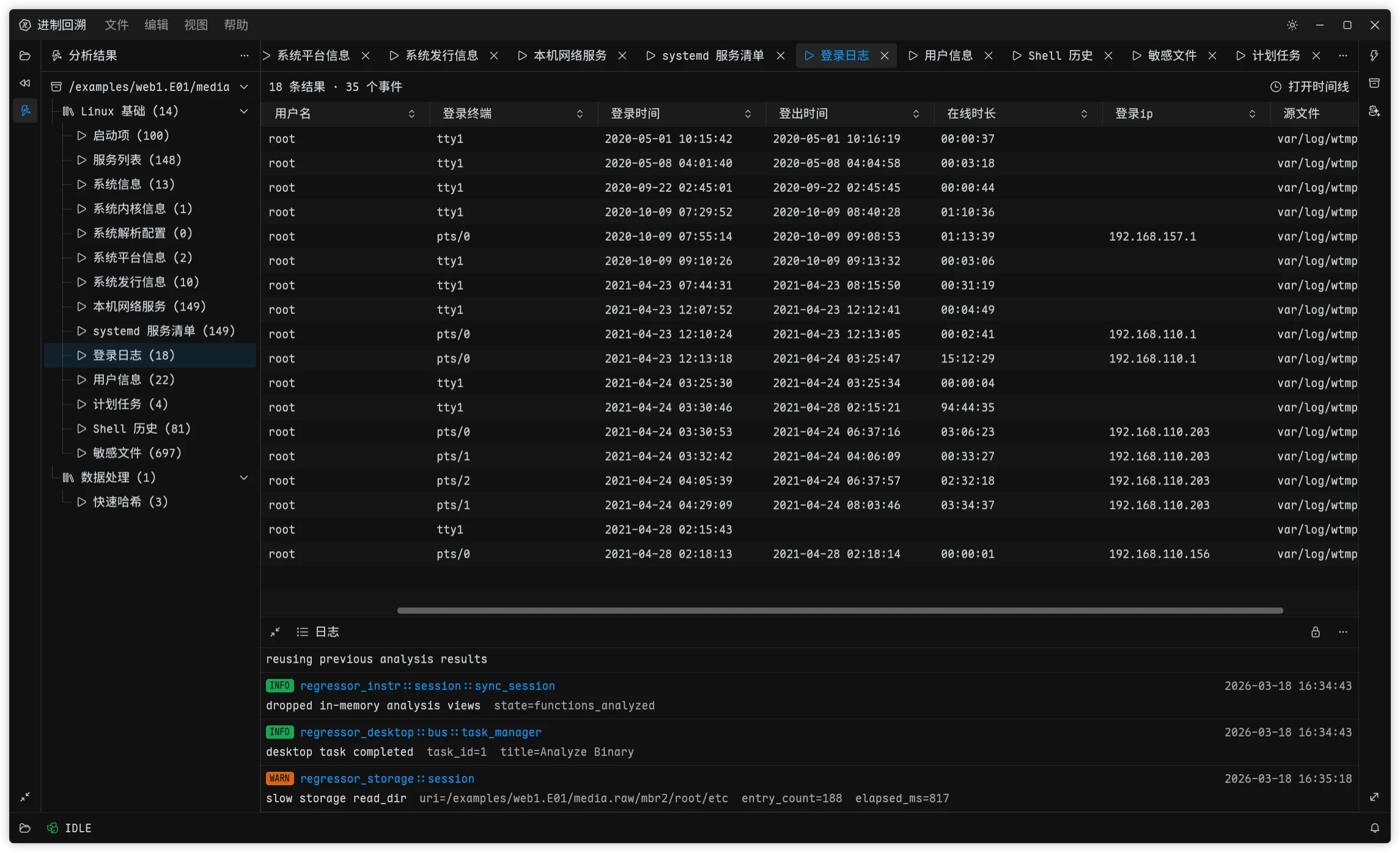
给 进制回溯 补取证能力的时候,我一开始并没有打算自己维护一套底层解析库。镜像、分区表、文件系统要做的事太多了,在本科期间构思取证猫的时候就有探索过 libyal,EWF、QCOW、VHDX、NTFS 这些格式每个都有一大堆的 RFC 标准文件要读要实现,类似 NTFS 这种被微软修修补补了几十年的屎山更难搞了。自己从零开始做,前期投入太大,覆盖面也很难迅速拉起来,甚至还要为了一些名为 feature 实为 bug 的玩意儿付出时间和精力。
不过就在我准备开始包装 libyal 到 Rust 库的时候,我偶然看到了 libyal 维护者当时正在做的事:keramics,他已经把 EWF、QCOW、VHD/VMDK、GPT、MBR、APM、NTFS、FAT、ext、HFS 这些格式用 Rust 语言重写了相当完整的只读支持。进制回溯只需要在在它的基础上构建一个 regressor-storage 设计一个桥接层,然后专心做整体架构的虚拟抽象就行了,镜像浏览、分区探测和文件系统挂载很快就能工作。
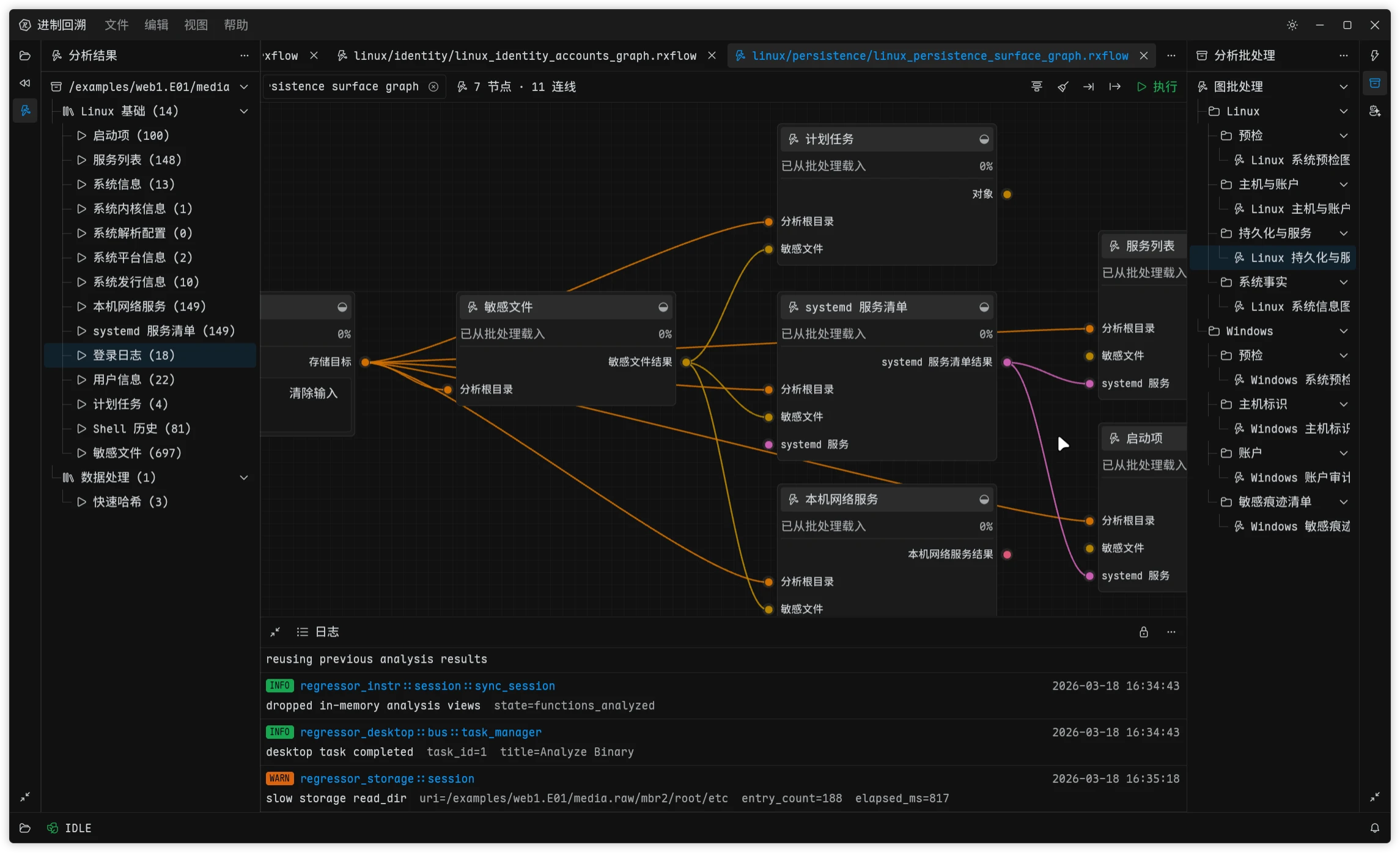
随着进制回溯的逐步开发,越来越多的问题也显现了出来,有两个越来越难绕开的事实:它的访问模型不适合目前的取证场景,你可能注意到了上面截图的日志中有一行慢读,这个就是 keramics 的架构设计导致的问题,keramics 库中整体使用了状态机设计模型,这导致了使用 keramics 支持的所有文件格式都无法进行真正的并发读写,虽然进制回溯做了比较完善的安全并发方案,访问到 keramics 驱动的时候还是会退化成单线程,导致一旦分析任务多起来,进制回溯就会变得异常卡顿,但是系统 CPU 占用和内存占用看起来都很低。
而且它在库级别上的 panic 风险,对取证场景来说已经很难接受。
并发访问的问题
进制回溯的存储层把原始字节源抽象成 DataSource,核心接口是按偏移读取:
fn read_at(&self, offset: u64, buf: &mut [u8]) -> Result<usize, _>;这个接口的好处很直接:调用方不需要关心共享 cursor,也不需要猜测另一个线程刚刚读取到了哪里,只要拿到这个数据源,就可以从文件的任意位置读取指定大小的数据,也不用担心并发访问的问题。 进制回溯里现在的哈希调度、probe cache 和 telemetry,都是基于这个模型构建的。
keramics 的核心抽象则是 DataStream。它的读操作依赖内部游标,基本形态仍然是 Seek + Read:
fn read(&mut self, buf: &mut [u8]) -> Result<usize, _>;
fn seek(&mut self, pos: SeekFrom) -> Result<u64, _>;单看这个接口并没有错,传统取证库里很多都是这样设计的。问题在于,一旦宿主要把它接到 read_at 语义上,桥接层就只能把每次随机读翻译成“先上锁,再改 cursor,再读取”,而这个 handle 里必然是存在一个状态来保存 cursor 位置的,这就不可能做到并发了。 在进制回溯现有的桥接实现里,这条路径最终只能声明成 Serialized + Expensive,而它彻底干掉了进制回溯对于并发读取的所有性能设计,分析侧本来已经实现了并发分块的快速哈希方案,但只要 keramics 这条适配路径没改,就必须退回顺序读取。
这种冲突还有一个特点:层级越多,代价越大。镜像里套分区,分区里套文件系统,文件系统里再挂归档或虚拟磁盘时,每一层都希望自己面对的是稳定的只读偏移源。只要最底下仍然依赖共享 cursor,上层做得再规整,最后都会被迫回到“这是不是一个串行后端”这个问题上。
库内 panic 风险
第二个严重问题,是它作为库时的失败方式。regressor 面对的是外部证据,输入天然不能信任。这里代价最大的情况不是读不出来,而是库里直接爆了给整个软件都带崩掉。 前者通常还能转成一条结构化错误,告诉用户某个样本不支持、损坏或者缺少 sidecar;后者在宿主里抓也抓不到,想靠 unwind 抓还要写一堆很丑的玩意儿去模拟 C++ 的 try catch,实在是难受。
keramics 目前的实现里仍然能看到一些建立在“这个状态理应存在”之上的 unwrap。例如 vhdx 读取 block allocation table 的路径里,就有直接对 self.block_allocation_table.as_ref().unwrap() 的访问。对独立工具而言,这种假设有时还能接受;但在长期运行的桌面程序和分析运行时里,它意味着一旦遇到畸形样本、实现分支遗漏,结果可能不是返回错误,而是把当前任务直接打断。
另一个工程问题是进制回溯为了接入 keramics,在桥接层里用共享锁包装了 DataStream。一旦底层某处 panic,锁就可能被 poison,后面的访问还会继续收到 LockPoisoned 这样的次生故障。也就是说,异常不一定停在第一次失败的位置,而是可能沿着共享状态继续传递。对取证库来说,这个代价太高了。解析器应该在坏输入面前尽量保守地失败,而不是把“某条内部假设失效”变成不稳定因素。
技术架构
基于上述问题,继续用 keramics 只会让后续开发工作越来越艰难,不如早点跑路自己写。正好现在 AI 能力都这么强了,写好基础设施之后让它照葫芦画瓢往里面塞各种文件系统 parser 实现,感觉它应该也不会写出来什么大问题。
于是,我打算接着写一套能够替代 keramics,API 设计更干净可用的东西出来。
项目名称其实是 Wired Xploring Target Layer Accessor 嗷,没有别的含义。
本项目开源在了 Reverier-Xu/wxtla,并发布在 crates.io 上。
第一层:数据源和能力描述
整个架构最底下是 core 里的数据源模型。DataSource 只保留按偏移读取和查询大小这两个最基本的动作,同时用 DataSourceCapabilities 明确描述后端的并发特征、seek 成本和建议块大小。这样做的意义在于,上层调度可以根据能力声明直接决定采用顺序读取还是并发分块,而不是通过实现细节去猜测后端性能。对解析器内部也是一样:元数据读取、内容读取、稀疏映射和父镜像回退,都可以建立在同一套接口上,不必再为每个格式补一层共享游标适配。
core 里另外几种包装器也是按这个原则安排的。SliceDataSource 负责把一个逻辑范围重新暴露成新的字节源,分区、镜像 extent 和文件内容都可以复用它。ProbeCachedDataSource 只缓存 probe 阶段前 64 KiB 内的小窗口读取,几十个格式在做签名判断时,不必反复读取同一段头部数据。ObservedDataSource 记录读次数、平均读大小、偏移跳跃距离和读耗时,让后面的性能分析和调度策略有实际数据可以参考。
第二层:probe 和相关源解析
wxtla 把格式识别单独做成了一层通用机制。FormatDescriptor 和 FormatKind 负责描述格式身份,FormatProbe 负责单个格式的判断逻辑,ProbeContext 提供带缓存的读取入口,ProbeRegistry 负责组织和排序 probe 结果。probe 的原则也比较明确:只做足够确认格式身份的小规模读取,不在这个阶段预解析整份镜像。对 regressor 这种要频繁执行自动挂载和递归探测的宿主来说,这个区分很重要。probe 一旦过重,整个存储层的响应都会受到影响。
与 probe 同样关键的,是 related source 的边界。EWF 的分段、QCOW 的 backing file、VHD/VHDX 的 parent image、sparsebundle 的 band,本质上都不是“当前文件内部”的问题,而是“当前对象引用了别的源”。 wxtla 不让 parser 直接访问主机文件系统,而是通过 SourceHints 把 SourceIdentity 和 RelatedSourceResolver 明确传入。RelatedPathBuf 也只是词法层面的相对路径,不带平台路径语义。这样一来,parser 只负责声明自己需要什么,真正的文件查找、工作区缓存命中和访问策略由宿主完成。这个边界直接决定了同一套 parser 能不能在不同运行环境里复用。
第三层:按领域划分的只读对象接口
在 core 之上,wxtla 没有再做一层统一 VFS,而是按数据域拆成了 images、volumes、filesystems 和 archives 四组接口。image driver 打开后仍然实现 DataSource,但会额外暴露逻辑扇区大小、物理扇区大小、是否稀疏、是否存在 backing chain 等格式语义。volume system driver 返回的是一组 VolumeRecord,里面只有 index、byte span、name 和 role 这些稳定信息,然后通过 open_volume 把对应逻辑卷重新打开成新的 DataSource。分区表因此只负责描述“这里有哪些卷”和“每个卷覆盖哪段字节”,不会提前替宿主决定 UI 结构或挂载方式。
文件系统和归档层采用的是同样的思路。FileSystem 提供 root node、node metadata、read_dir 和 open_file;Archive 提供 entry metadata、read_dir 和 open_file。无论是 FileSystemNodeId 还是 ArchiveEntryId,都是不透明标识,而不是把路径字符串拿来当内部主键。这样可以把路径归一化、挂载点拼接、展示名称和访问控制这些产品层面的事情留在宿主里处理,解析器内核只保留稳定的结构标识和内容读取能力。
第四层:格式模块的组织方式
具体到实现组织,wxtla 也尽量避免中心化。每个格式模块自己声明 descriptor、自带 probe,并通过 inventory::submit! 把注册信息提交到 inventory。formats/ 目录只负责把这些离散条目组装成 probe registry,而不再维护一张越来越大的中心分发表。这样修改某个格式时,定义、probe 和 open 逻辑基本都能留在同一个模块边界里,维护成本要小得多。
非平凡格式的内部结构也有比较稳定的分工。mod.rs 负责导出和注册;低层结构体负责 header、entry、table 这类固定布局的解析;parser.rs 负责组织元数据读取与一致性校验;image.rs、system.rs、filesystem.rs 或 archive.rs 负责把解析结果变成可读对象表面。缓存也尽量留在格式内部,例如 chunk cache、block translation table、extent cache 和按分配单元的解压缓存。这样做的好处是局部优化不会污染整个 core,不同格式之间也不需要围绕同一套统一的大缓存框架反复协调。
第五层:错误模型和 panic 约束
wxtla 的最后一条架构约束,是把失败路径当成设计的一部分。core 层只保留几类稳定错误:I/O 错误、UnexpectedEof、InvalidRange、InvalidFormat、InvalidSourceReference 和 NotFound。具体格式可以附加自己的上下文,但最外层行为必须一致:遇到损坏样本、非法偏移、缺失 related source 或不支持的特性时,返回结构化错误,而不是依赖 panic 去暴露问题。配合 checked_*、try_from 和先验证再解码的规则,wxtla 的目标不是“代码看起来更整洁”,而是让解析库在面对真实证据时保持可预测。
从这几层分工来看,wxtla 的角色就比较清楚了:它只把字节解释成 image、volume、filesystem、archive 这些稳定的只读对象;再由 regressor-storage 负责把这些对象适配进 StorageSession 和 MountedFilesystem。这样既能复用同一条访问链路,也能避免解析器和宿主再次出现职责交叉。
重构进制回溯
对进制回溯来说,这次重写把绝大部分的格式解析能力都拆到了 wxtla,存储模块本身的设计可以简化非常多,也不必再为了并发访问单独设计兼容层或者桥接。桌面端、分析运行时和 Python bridge 依赖的是 StorageSession、MountedFilesystem 和 DataSource,同样也不依赖某个特定的格式。只要这层宿主接口不变,进制回溯现有的架构并不需要跟着做一次大手术。